Robots.txt files are commonplace on the Web and standard for most CMS platforms. Even if you don’t know what a robots.txt file is, it is likely that your site has one. As a brief summary, a robots.txt file is a plain-text, or .txt file, that lives in the root directory of your website. This file allows webmasters to give instructions to web robots on how to crawl their site. A site’s robots.txt file can be found at domain.tld/robots.txt. In theory, your robots.txt file will be the first file crawled and web robots will then use these directives on how to crawl, or not to crawl, the site. Malware bots etc. are going to ignore your robots.txt file completely and crawl your site. In fact, your web logs will reveal that most bots ignore your robots.txt specifications, but the question is does Google obey your robots.txt file exclusions?
Does Google Obey Your Robots.txt File Exclusions?
I want to keep this brief, so all I’m checking is if Google obeys your robots.txt exclusions. Common exclusions and their meanings:
Directive to instruct all robots or web crawlers:
User-agent: *
Directive to instruct just Google bot:
User-agent: Googlebot
Disallow all pages:
Disallow: /
Disallow Certain Pages/Directories
(common disallow for WordPress sites):
Disallow: /wp-admin/
Disallow all bots from entire site:
User-agent: *
Disallow: /
Disallow all bots from WP admin directory:
Disallow: /wp-admin/
With that covered, I have disallow all admin pages enabled for my site. So, does Google obey my robots.txt file exclusions?
Well, yes and no. I don’t see my excluded directories in the primary results, but I do see my root admin page in the “omitted” results:
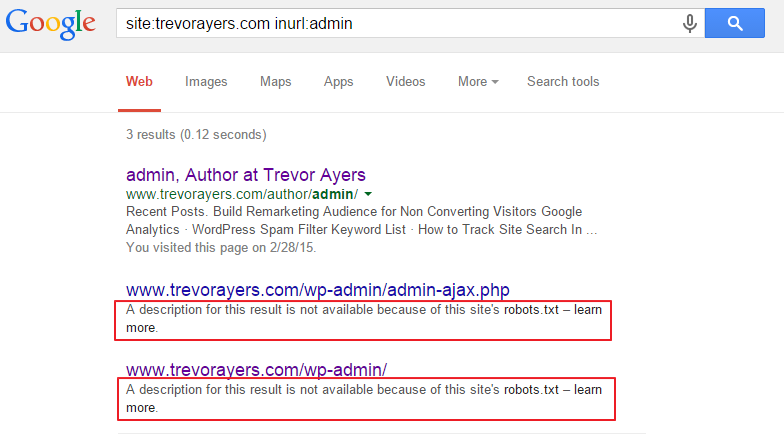
However, results differ if you have your root domain excluded via your robots.txt file. These results are visible in search results and not hidden behind the “omitted” results:
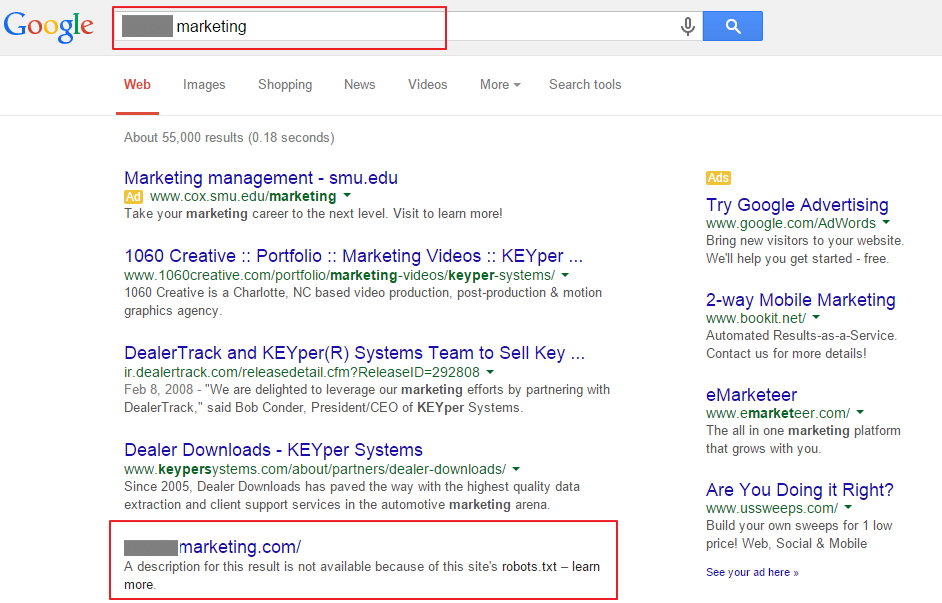
Note with the second result that this is not a search specifying the domain, but rather the brand and the robots.txt exclusion is being ignored. Though, the page description and actual title is not being displayed in search results. The cache is also not available for either of these results. However, it is clear that Google will still return your site with a robots.txt exclusion, though, it will certainly cripple your SEO.
*This post is not about Bing, but in all examples I’ve found Bing does honor the robots.txt exclusions and does not return these results.
Google Does Not Obey Your Robots.txt File Exclusions – How Can You Stop Your Pages From Returning in Searches?
You will need to add the below no index, and no follow meta tag in the <head> tags on your site:
<meta name=”robots” content=”noindex, nofollow”>
You can also allow following and just disallow indexing:
<meta name=”robots” content=”noindex” />
There you go, Google does not obey your robots.txt exclusions. However, you can still keep your site private in a number of ways.